Auf Spurensuche: Non-Target-Screening in der Wasseranalytik

Wasser ist eine der wichtigsten Ressourcen unseres Planeten. Es dient dabei nicht nur als notwendiges Nahrungsmittel, sondern ebenso als Transportmedium z.B. für die Schifffahrt, als Lösungsmittel für viele chemische und biologische Prozesse oder als Energieressource.
Wasser ist jedoch nicht gleich Wasser und besteht natürlicherweise aus tausenden verschiedenen gelösten und partikulären Spurenstoffen. Viele von ihnen sind wichtige Bestandteile für die Funktionen, Prozesse und Kreisläufe des Wassers. Besonders Ökosysteme reagieren zumeist sehr empfindlich auf bereits kleinste Veränderungen der Zusammensetzung.
Durch uns Menschen gelangen viele verschiedene Schadstoffe in Gewässer. Zum Beispiel werden Medikamente, die wir einnehmen, aus dem Körper teilweise wieder ausgeschieden und landen so über unsere Kläranlagen in den Flüssen. Abb. 1 zeigt ein Schema einiger Eintragsquellen des Menschen.
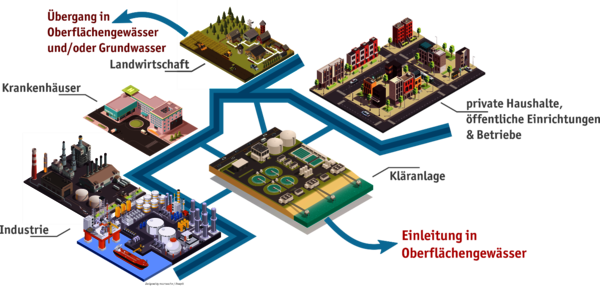
Abb. 1: Typische Szenarien, wie Schadstoffe durch den Menschen in die Umwelt bzw. Gewässer gelangen können. (Graphik: G.Renner, L.Hohrenk-Danzouma, unter Verwendung von macrovector/Freepik.com)
Wichtig: Überwachung der Wasserqualität
Im Abwasser lassen sich aber auch viele andere Substanzen, die für Lebewesen im Wasser gefährlich werden können, z.B. aus Reinigungsmitteln oder Kosmetikprodukten, wiederfinden. Auch Pflanzenschutzmittel, die wir in der Landwirtschaft einsetzen, können über Regen in die Gewässer gespült werden. Die meisten dieser Schadstoffe liegen in sehr geringen Konzentrationen vor und werden typischerweise als „Mikroschadstoffe“ bezeichnet.
In Deutschland ist der Umgang mit Wasser und wassergefährdenden Stoffen in den allermeisten Fällen gesetzlich geregelt, um Mensch und Umwelt einen möglichst guten Schutz zu bieten. Beispiele hierfür sind das Wasserhaushaltsgesetz [1] oder die Trinkwasserverordnung [2]. Übergreifend wurde im Jahr 2000 die europäische Wasserrahmenrichtlinie verabschiedet, um eine gute Wasserqualität in der EU sicherzustellen [3].
Die Qualität bzw. Zusammensetzung des Wassers spielt eine entscheidende Rolle und es erfordert gut ausgebildete analytische Chemiker*innen und leistungsstarke analytische Messmethoden, um diese zu untersuchen. Ganz allgemein gibt es in unseren Gewässern eine große Vielfalt verschiedener Substanzen, die über unterschiedlichste Wege in die Gewässer gelangen. Diese können sich sogar weiter verändern, so dass eine wilde Mischung aus teilweise unbekannten Stoffe entsteht. Hier den Überblick zu behalten und gefährliche von harmlosen Substanzen zu unterscheiden, ist eine der großen Herausforderungen der Wasseranalytik.
Heutzutage ist es möglich wenige Nanogramm, d.h. 0,000000001 g einer Substanz nachzuweisen. Zum Vergleich: ein einzelnes Staubkorn ist dagegen ein echtes Schwergewicht und wiegt rund das Tausendfache. Solche großen Nachweisstärken werden in der Regel benötigt, um besonders gefährliche Schadstoffe auch dann zu erkennen, wenn ihre Wirkungen auf Ökosysteme noch nicht sichtbar sind. Für Frühwarnsysteme und Präventivmaßnahmen kann dies ein entscheidender Faktor sein. Ein Beispiel für solche Schadstoffe sind Neonicotinoide, die aufgrund ihrer besonders starken toxischen Wirkung auf Insekten im Pflanzenschutz angewendet werden. Der Einsatz vieler Neonicotinoide ist umstritten und in Deutschland und Teilen der EU verboten. Weiterführende Informationen gibt es beispielsweise hier [4].
Der Chemische Fingerabdruck
Bei genauerer Betrachtung weisen Gewässer eine sehr charakteristische Zusammensetzung der vielen tausend Inhaltsstoffe auf. Vergleicht man verschiedene Gewässer, z.B. den Rhein, die Donau oder den Chiemsee, gibt es natürlicherweise Ähnlichkeiten, d.h., Inhaltstoffe die allgegenwärtig erscheinen, aber auch große Unterschiede. Ebenso können saisonale Effekte z.B. Jahreszeiten oder auch globale Trends wie z.B. der Klimawandel die Zusammensetzung der Gewässer direkt oder indirekt beeinflussen.
Das Herausarbeiten dieser Ähnlichkeiten und Unterschiede ist eine der Herausforderungen der modernen Wasseranalytik. Sind die Zusammensetzung und das Verhalten eines Gewässers bekannt, können somit z.B. Stoffe identifiziert werden, die nicht ins Wasser gehören. Dabei ist es sogar möglich, Hinweise auf noch völlig unbekannte Substanzen zu erhalten, welche dann anhand von Computersimulationen modelliert und identifiziert werden können. Um all diese komplexen Aufgaben zu lösen, wird zunehmend eine „nicht-ziel-gerichtete“ Analytik, das Non-Target-Screening (NTS), genutzt.
Das Ziel des Non-Target-Screenings (NTS) ist es, möglichst viele Informationen aus einer (un)bekannten Probe herauszuziehen, d.h. möglichst alle Inhaltstoffe zu erfassen. Typischerweise wird dabei für das NTS in der Wasseranalytik ein Hochleistungsflüssigkeitschromatograph (HPLC, High Performance Liquid Chromatography) in Kombination mit einem hochauflösenden Massenspektrometer (HRMS, High Resolution Mass Spectrometer) verwendet. Im Kern handelt es sich dabei um eine zweistufige Messmethode. Die einzelnen Verfahren bzw. Prinzipien sind dabei nicht neu und wurden bereits vor über 100 Jahren von Wissenschaftler*innen wie Joseph J. Thompson, Arthur Jeffrey Dempster oder Michail S. Tswett, publiziert. (Zu Non-Target-Analytik siehe auch Schutz von Mensch und Tier: Lebensmittelanalytik.)
Hochleistungsflüssigkeitschromatographie (HPLC) und hochauflösende Massenspektrometrie (HRMS)
In der ersten Stufe, der Chromatographie, werden die verschiedenen Inhaltsstoffe der Probe (Analyten) aufgetrennt. Dazu wird die Messlösung mit einem speziellen Lösungsmittel, dem Eluenten, durch eine Trennsäule gepumpt. Diese ist mit kleinen, speziell beschichteten, Kügelchen gefüllt und wird als stationäre Phase bezeichnet. Die einzelnen Inhaltsstoffe der Probe bilden Wechselwirkungen mit der Beschichtung des Trennsäulenmaterials aus. Dadurch kommt es zu einer Anlagerung und Migration der Analyten an bzw. in die Beschichtung. Diese Wechselwirkungen stehen allerdings in Konkurrenz zum Eluenten, welcher die Substanzen von der Beschichtung wieder ablöst und kontinuierlich zum Ausgang der Säule transportiert. Die Analyten verharren daher immer nur kurzzeitig an der stationären Phase. Unterschiedliche chemische Verbindungen weisen unterschiedliche starke Wechselwirkungen auf und verbleiben daher unterschiedlich lang in der Trennsäule – es kommt zur Auftrennung der Probe.
Nach dem Chromatographen werden die aufgetrennten Moleküle ionisiert, d.h. elektrisch geladen und anschließend in das Massenspektrometer geleitet. In dieser zweiten Stufe des Messverfahrens wird das Masse/Ladungs-Verhältnis (m/z) der Moleküle gemessen, welches wiederum Aufschluss auf die eigentliche Molekülmasse geben kann. Dazu wird erneut eine hoch charakteristische Wechselwirkung der unterschiedlichen Moleküle ausgenutzt. Diesmal jedoch nicht mit einer stationären Phase, sondern mit einem elektrischen Feld. Je nach m/z verhalten sich geladene Moleküle im elektrischen Feld unterschiedlich und lassen sich z.B. unterschiedlich schnell beschleunigen oder unterschiedlich stark in ihrer Flugbahn beeinträchtigen.
Eine Bauart eines Massenspektrometers ist beispielsweise das Flugzeit-Massenspektrometer, welches, wie der Name vermuten lässt, die Zeiten misst, die unterschiedliche Molekülionen benötigen, um eine definierte Strecke zurückzulegen, nachdem diese in einem elektrischen Feld beschleunigt worden sind. Moderne Messsysteme können dabei die Molekülmasse auf drei bis vier Nachkommastellen genau bestimmen. Dies ist notwendig, denn je genauer die Molekülmasse bestimmt werden kann, desto weniger mögliche Substanzen kommen für eine Identifizierung in Frage. So liefert eine Datenbankabfrage bei der offenen Datenbank PubChem [5] für den Massenbereich von 200 ± 0,1 g/mol bereits 2916 verschiedene Einträge. Verringert man den Massenbereich bzw. erhöht die Genauigkeit auf 200 ± 0,01 g/mol, verbleiben immer noch 166 chemische Verbindungen.
Big Data und Künstliche Intelligenz
Eine Analyse einer Probe besteht aus ca. 50.000.000 einzelnen Messungen und dauert ca. 25-30 Minuten. In jeder dieser Messungen wird dabei für die jeweiligen chemischen Verbindungen die Zeit für den Durchlauf im Chromatographen (Retentionszeit rt), das m/z und die Signalintensität aufgezeichnet. Während rt und m/z wichtige Informationen über die Art des jeweiligen Moleküls beinhalten, gibt die Signalintensität Aufschluss über die Menge bzw. Konzentration der Inhaltstoffe. Alles in allem sind die Datenmengen aber viel zu groß, um diese einzeln zu betrachten. Daher wird vermehrt auf automatisierte Verarbeitung und Auswertung der riesigen Messdatensätze gesetzt.
Nicht jeder Datenpunkt steht für eine eigene chemische Substanz in einer Probe; vielmehr verlassen Moleküle einer Substanz die Trennsäule der Chromatographie in einem für die Substanz charakteristischen Zeitfenster von mehreren Sekunden. Außerdem gibt es auch kleinste Variationen des ermittelten Masse/Ladungs-Verhältnisses innerhalb einer Molekülart, so dass für eine chemische Verbindung eine Vielzahl von Datenpunkten aufgezeichnet wird, die in gewissen Grenzen schwankt. Bildlich könnte man sich diesen Vorgang als Marathonlauf vorstellen. Auch hier kommen nicht alle Läufer*innen zur gleichen Zeit ins Ziel, sondern in einem gewissen Zeitfenster. Wenige sind dabei ganz vorn oder ganz weit hinten und die allermeisten befinden sich im Hauptfeld der Läufer*innen. Hier kann man dann die Durchschnittszeit ermitteln, die die Läufer*innen für die Strecke benötigen.
Bei der HPLC-HRMS ist dies ähnlich. Moleküle einer chemischen Verbindung, z.B. das Insektizid Imidacloprid, werden nicht alle zeitgleich, sondern in einer gewissen Verteilung das Messsystem passieren. Als Gruppe beschreiben sie jedoch eine einzige chemische Verbindung. Im bildhaften Beispiel des Marathonlaufs wäre eine zweite chemische Verbindung, wie das Antidiabetikum Metformin, z.B. eine Gruppe von Radfahrer*innen. Diese bewegen sich deutlich schneller, zeigen aber ebenfalls ein Verteilungsmuster, betrachtet man sie als Gruppe. Im Non-Target-Screening variiert allerdings nicht nur die Zeit, in der die unterschiedlichen Analyten das Messsystem passieren, sondern auch das Substanzspezifische Masse/Ladungs-Verhältnis. Dies kann grafisch durch einen Isoplot dargestellt werden, was in Abb. 2 zu sehen ist. Je nach Zusammensetzung der Probe zeigt diese Darstellung ein charakteristisches Muster.
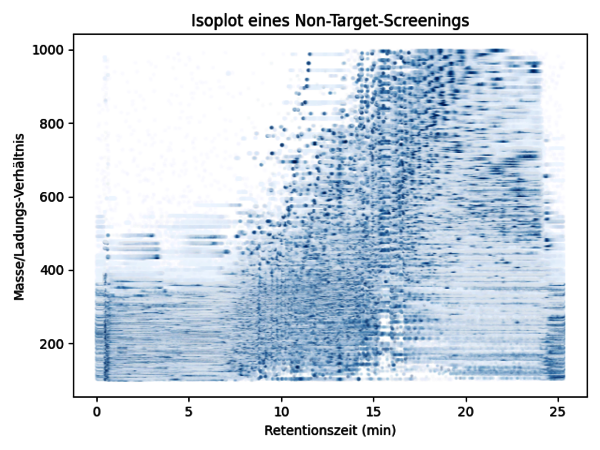
Abb. 2: Darstellung eines Non-Target-Screenings einer Gewässerprobe (Zulauf einer kommunalen Kläranlage). Die Messdaten sind als Punktwolke dargestellt. Die Farbintensität zeigt dabei die Signalintensität an. Die verschiedenen Analyten sind als verdichtete dunkelblaue Cluster zu erkennen. (Quelle: Hohrenk, Lotta L., et al. "Comparison of software tools for liquid chromatography–high-resolution mass spectrometry data processing in nontarget screening of environmental samples." Analytical chemistry 92.2 (2019): 1898-1907.)
Die Hauptaufgabe der Datenverarbeitung im Non-Target-Screening ist es, einzelne Datenpunkte zu Gruppen zusammenzufassen und charakteristische Eckdaten für diese Gruppen, auch Features genannt, zu erheben, wie z.B. die mittlere Zeit, m/z und Gesamt-Signalintensität der Gruppe. Hierfür greifen wir Analytiker*innen entweder auf bereits existierende Auswertungsprogramme zurück, oder entwickeln und programmieren eigene Algorithmen; speziell zugeschnitten, um zu bestimmten Fragestellungen zu forschen. Eine erfolgreiche Zusammenfassung der Messdaten reduziert den Datensatz bereits beträchtlich, sodass ca. 1.000 bis 10.000 Features übrigbleiben.
Durch die Zusammenfassung wurde die Information aus dem ursprünglichen Messdatensatz stark verdichtet und kann nun als kompakte Feature-Liste mit anderen Proben oder einer Datenbank verglichen werden, um die anfangs erwähnten Unterschiede und Gemeinsamkeiten zu identifizieren. Auch hierfür werden zumeist computergestützte Algorithmen verwendet, die in ähnlicher Weise funktionieren wie z.B. die Gesichts- oder Fingerabdruck-Erkennung unserer Smartphones – ein Datensatz wird als Muster aufgefasst, welches sich aus kleinen Elementarbausteinen zusammensetzen lässt.
Die Anordnung der Bausteine zueinander ist für jedes Muster z.B. Fingerabdruck hoch charakteristisch. Liegt ein Vergleichsmuster vor, können Bereiche des Musters markiert werden, welche sich ähneln bzw. sich stark unterscheiden. Nehmen wir beispielsweise eine Wasserprobe des Rheins vom April 2021 und vergleichen diese mit einer Wasserprobe des Rheins vom März 2021 oder gar vom April 2020, werden wir auf Unterschiede und Gemeinsamkeiten in den Feature-Listen stoßen. Entweder, weil neue Substanzen auftauchen oder andere verschwinden, oder weil sich die Konzentrationen der einzelnen Inhaltsstoffe stark ändern. Wir können dadurch herausfinden, wie sich ein Gewässer über die Zeit verändert.
Natürlich spielt auch der Ort, an dem die Probe entnommen worden ist, eine sehr wichtige Rolle. So ist auch zu erwarten, dass sich die Zusammensetzung eines Fließgewässers von der Quelle bis zur Mündung vielfach ändern kann. So können unter anderem auch Schadstoffquellen identifiziert werden, was Matthias Ruff et al. in einer Studie zeigen konnte. Dabei haben die Wissenschaftler*innen entlang des Rheins Gewässerproben untersucht und über 130 verschiedene Mikroschadstoffe gefunden [6].
Die Herausforderungen von Morgen
Die Analytik und so auch das Non-Target-Screening wird von Tag zu Tag weiterentwickelt und stetig verbessert. Und doch gibt es bisher einige ungelöste Herausforderungen, die wir und zukünftige Wissenschaftler*innen bewältigen müssen. Ein besserer Umgang mit den Messdaten und deren Auswertung und Interpretation ist sicherlich eine dieser Herausforderungen. Zwar gibt es hierfür bereits viele unterschiedliche Ansätze und bemerkenswert leistungsstarke Algorithmen, vergleicht man jedoch die Ergebnisse verschiedener Auswertungsmethoden untereinander, kann man teils große Unterschiede feststellen.
Dadurch ist oft unklar, welcher der Algorithmen welches Feature in den jeweiligen Datensätzen besser bestimmen kann. In eigenen Untersuchungen konnten wir in diesem Zusammenhang zeigen, dass je nach Einstellung des Auswertungs-Algorithmus, Ergebnisse signifikant variieren können, obwohl der zugrundeliegende Messdatensatz derselbe ist. Ob ein Ergebnis richtig oder falsch ist und welche Einstellung sich am besten eignet, kann überdies oft nicht aufgeklärt werden, da die meisten Inhaltsstoffe der Probe bisher unbekannt sind. Man weiß also zuvor nicht, was man findet, geschweige denn, was man sucht. In einer Vergleichsstudie konnten Lotta Hohrenk et al. zeigen, dass nur ca. 10 % der Ergebnisse bzw. gefundenen Features übereinstimmen, wenn verschiedene Auswertungsalgorithmen verwendet werden, um dieselben Datensätze auszuwerten [7]. Dies zeigt uns, dass es die eine Strategie bzw. den einen Algorithmus, der alle Messdaten perfekt auswerten kann, noch nicht gibt. Die Studienergebnisse zeigen uns aber auch, dass es durchaus sehr sinnvoll ist, je nach Fragestellung verschiedene Auswertungskonzepte anzuwenden; denn jede Methode hat sicherlich Stärken und Schwächen.
Hinzukommt, dass auch Algorithmen nicht fehlerfrei sind und teilweise Features bzw. Substanzen erkennen, die nicht in der eigentlichen Probe enthalten sind. Typischerweise sind solche Phänomene auf Verunreinigungen oder Messartefakte zurückzuführen, die in jeder Messung vorkommen. Bei diesen Phänomenen handelt es sich um zufällig entstehende Signalintensitätsspitzen bzw. zufällige Muster in den Signalverläufen. Noch sind unsere Algorithmen nicht in der Lage, solche „falsch-positiven“ Ergebnisse vollständig auszuschließen, sodass immer wieder von Hand stichprobenartig kontrolliert werden muss.
Trotz dieser noch offenen Herausforderungen ist das Non-Target-Screening bereits jetzt ein sehr mächtiges Werkzeug in der Umweltschutzanalytik.
Ergänzung: Mai 2024: unter Gewässeranalytik: Spurenstoff-Tracking mit KI finden Sie einen aktuellen Beitrag zu NTS mit Hilfe von Künstlicher Intelligenz (KI)


Dr. Gerrit Renner und Lotta Hohrenk-Danzouma
Universität Duisburg-Essen, Fakultät für Chemie, Instrumentelle Analytische Chemie
Literatur und Quellen
[1] https://www.gesetze-im-internet.de/whg_2009/
[2] https://www.gesetze-im-internet.de/trinkwv_2001/BJNR095910001.html
[3] https://eur-lex.europa.eu/eli/dir/2000/60/oj?locale=de
[4] https://www.bund.net/umweltgifte/pestizide/wirkstoffe-von-pestiziden/neonikotinoide/
[5] https://pubchem.ncbi.nlm.nih.gov
[6] https://doi.org/10.1016/j.watres.2015.09.017
[7] https://doi.org/10.1021/acs.analchem.9b04095
Weitere Beiträge aus der Analytischen Chemie
Speziationsanalytik – das Detail zählt!
Lumineszenz: Warum ein Standard wichtig ist
Eine Analysentechnik mit Potenzial
Ein Bild sagt mehr als tausend Worte
Dem Leben auf der Spur – Einzelzellanalytik
Auf Spurensuche: Non-Target-Screening in der Wasseranalytik
Schaffe ich den Marathon? – Bioprofilierung
Ursprung des Lebens
Was haben eigentlich Tropfsteine mit dem Klimawandel zu tun?
Ein schwieriges Thema: Glyphosat
Gar nicht so einfach – der Nachweis von Fluor (BAM)
Nachweis chemischer Kampfstoffe: Serumalbumin, das Gedächtnis unseres Körpers
Instrumentelle Analytik im Einsatz gegen Chemische Kampfstoffe
Methan in der Atmosphäre – satellitenbasierte Analyse eines Treibhausgases
Kaum größer als ein Schuhkarton: Mobiler Sensor für Sprengstoffe
Smarte Produktion: Modulare Systeme für die Synthese von Spezialchemikalien
Lithium-Ionen-Akkus untersuchen (BAM)
Termiten verstehen (BAM)
Schokolade: Genuss ohne unerwünschte Zusatzstoffe (BAM)
Schnelltest für stillende Mütter (BAM)
Lebensmittelfälschern auf der Spur (BAM)
Kommentare
Keine Kommentare gefunden!